Lecture 18: Outliers and Robust Regression
STA702
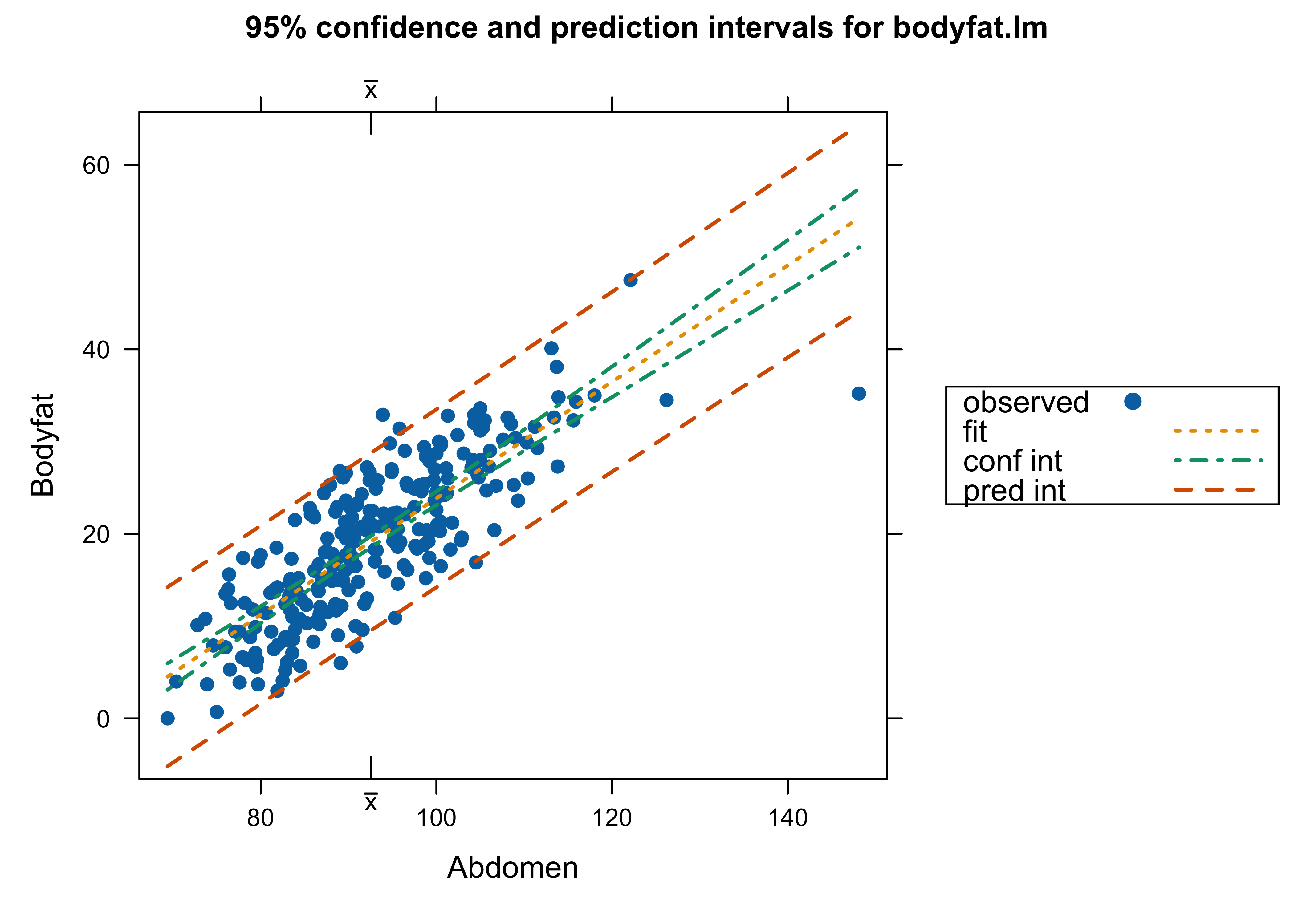
Body Fat Data
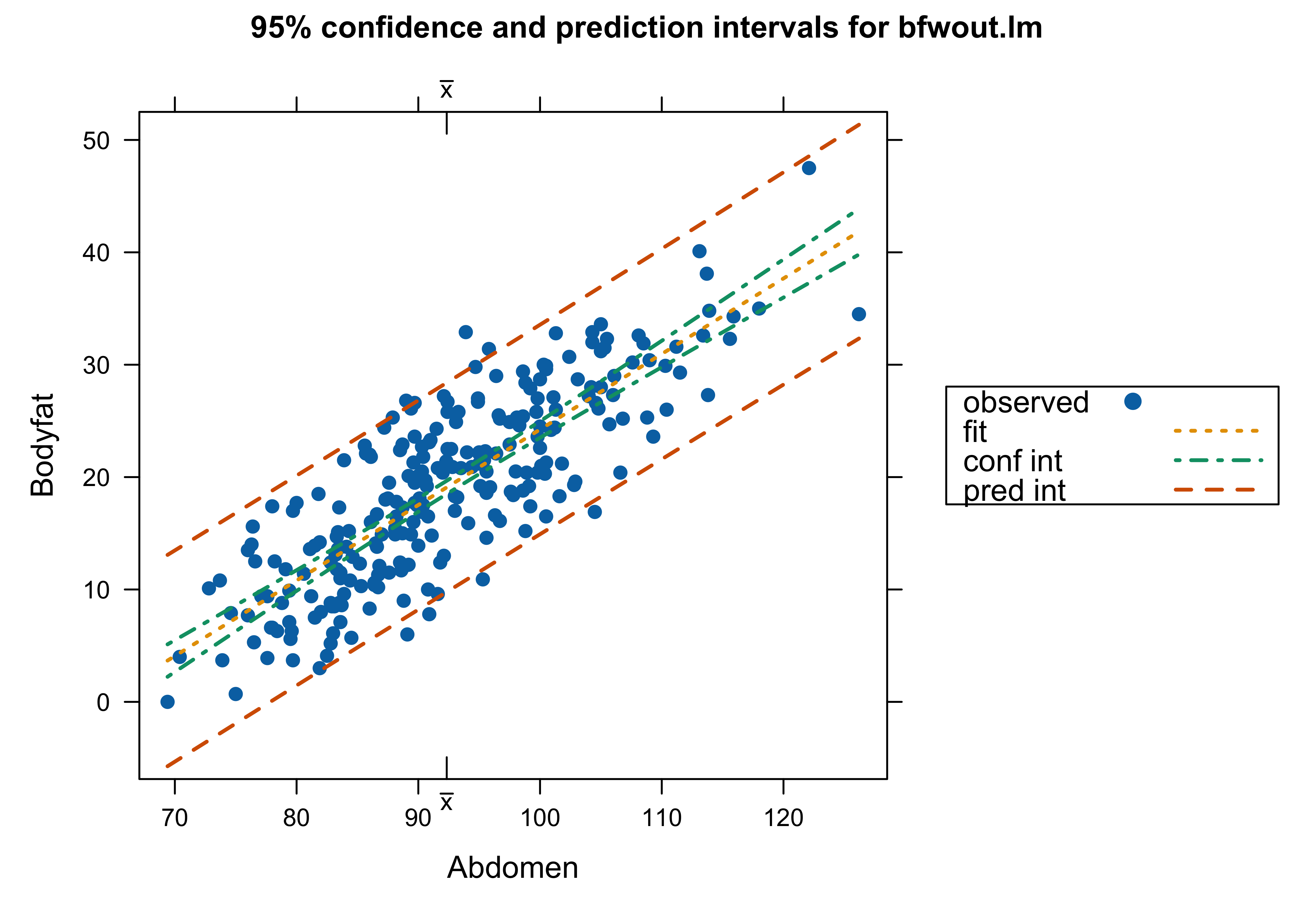
Which analysis do we use? with Case 39 or not – or something different?
Cook’s Distance

BAS with Truncated Prior

Choice of df for Student-\(t\)
Investigate the Score function \[ \frac{d} {d \boldsymbol{\beta}} \log p (\boldsymbol{\beta}\mid \mathbf{Y}) = \frac{d} {d \boldsymbol{\beta}} \log p(\boldsymbol{\beta}) + \sum_{i = 1}^n \mathbf{x}_i g(y_i - \mathbf{x}^T_i \boldsymbol{\beta}) \]
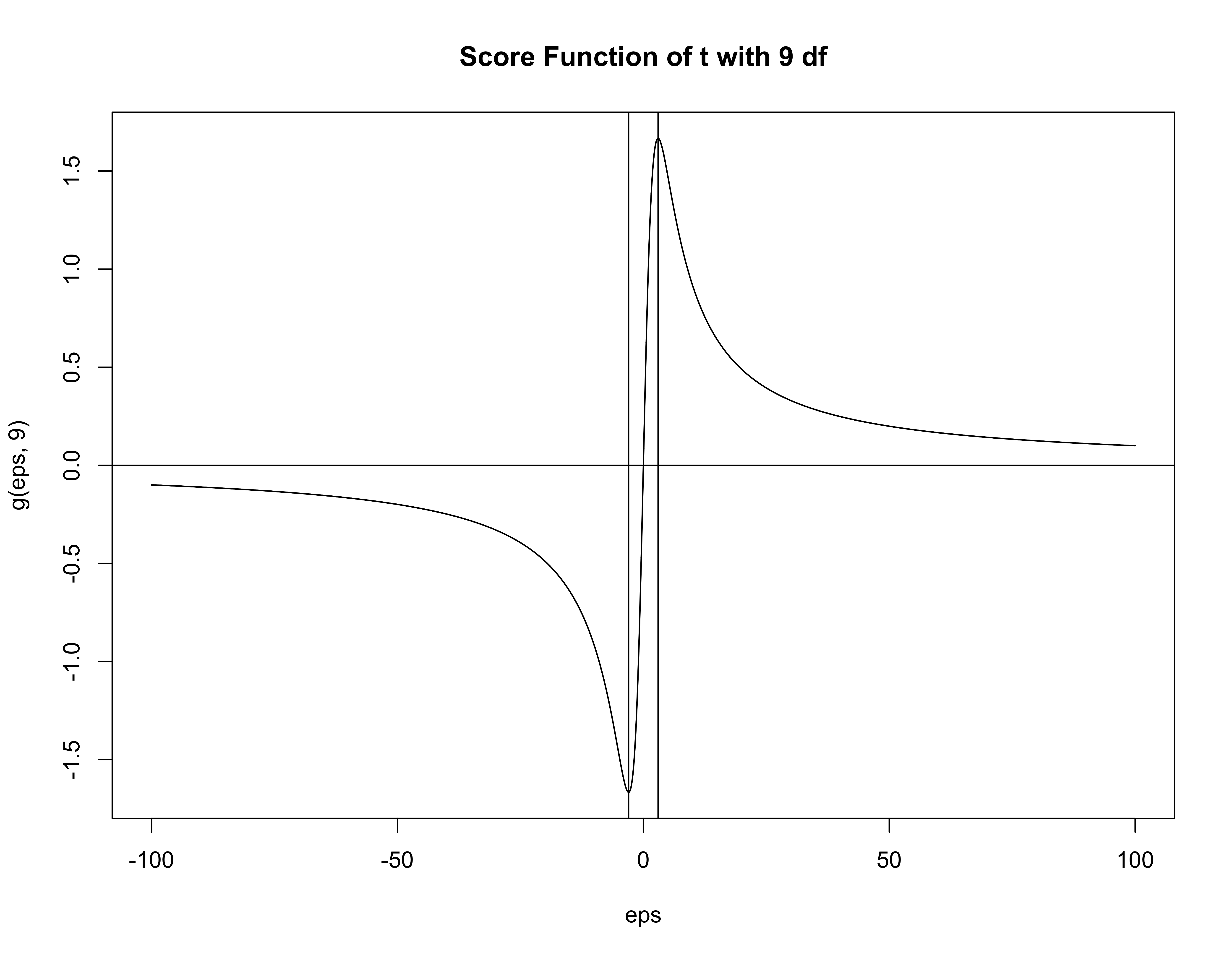
Score function for \(t\) with \(\alpha\) degrees of freedom has turning points at \(\pm \sqrt{\alpha}\)
\(g'(\boldsymbol{\epsilon})\) is negative when \(\boldsymbol{\epsilon}^2 > \alpha\) (standardized errors)
Contribution of observation to information matrix is negative and the observation is doubtful
Suggest taking \(\alpha = 8\) or \(\alpha = 9\) to reject errors larger than \(\sqrt{8}\) or \(3\) sd.
Posterior Distributions
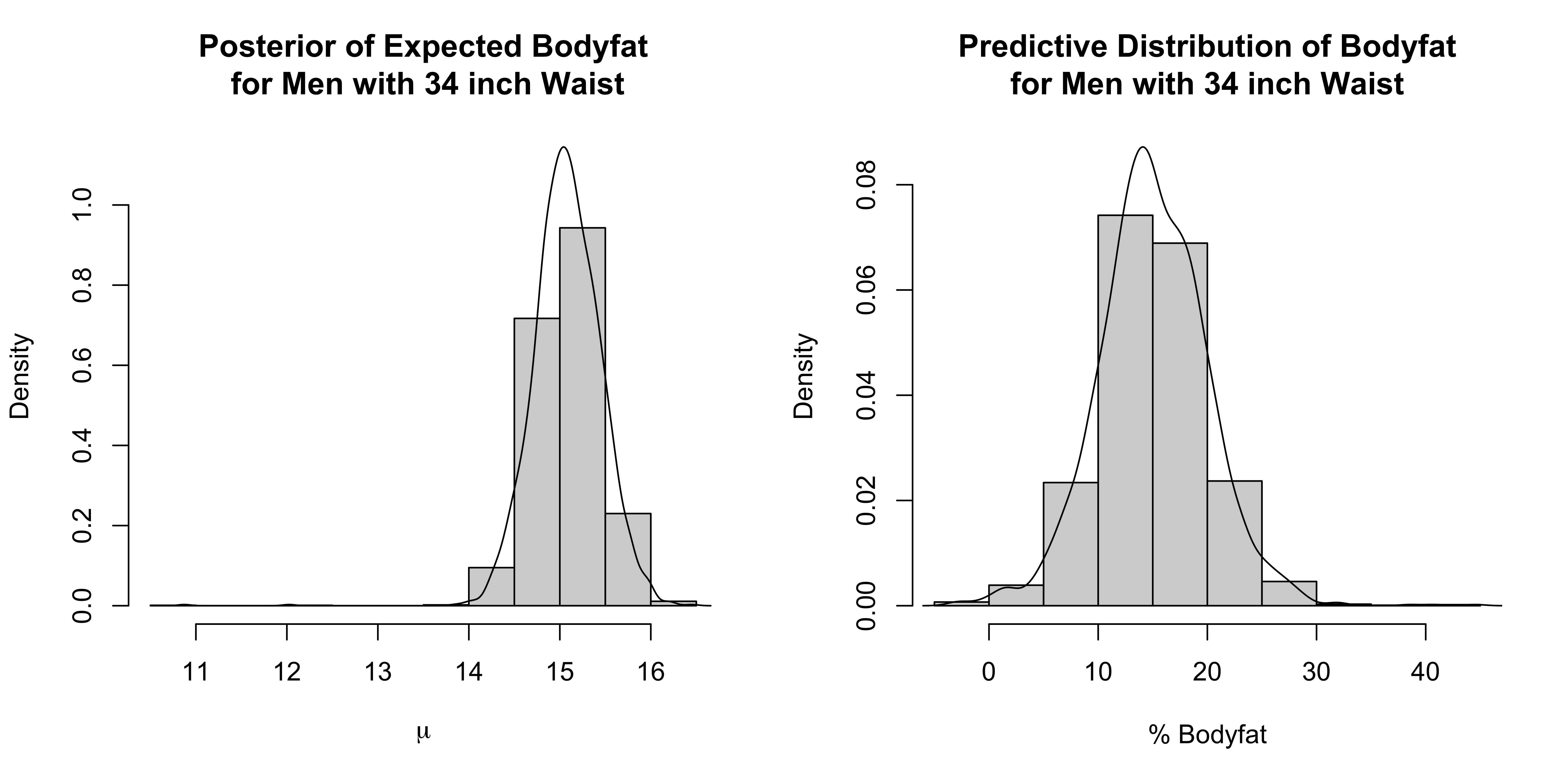
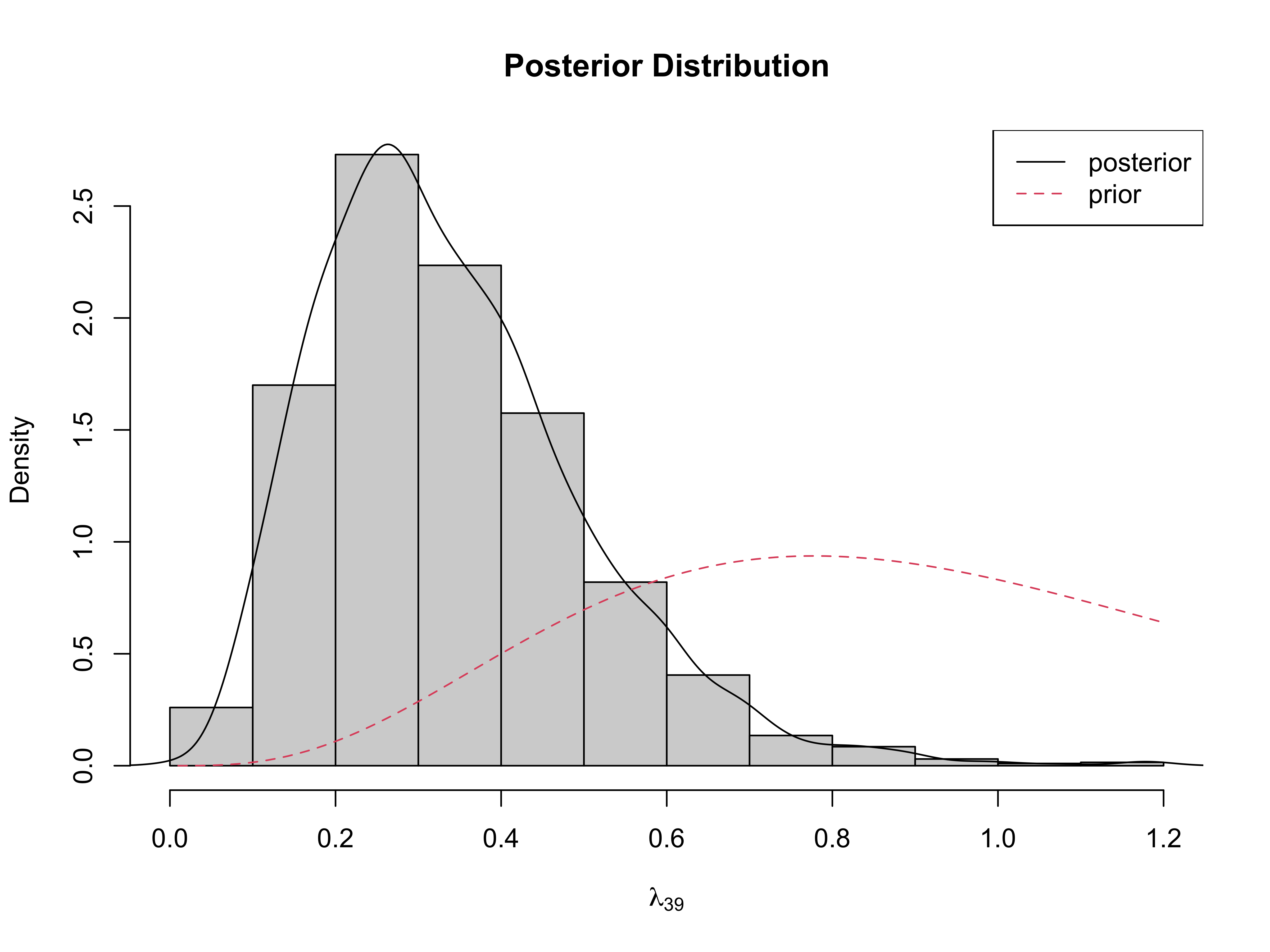
Posterior of \(\lambda_{39}\)
Summary
Classical diagnostics useful for EDA (checking data, potential outliers/influential points) or posterior predictive checks
BMA/BVS and Bayesian robust regression avoid interactive decision making about outliers
Robust Regression (Bayes) can still identify outliers through distribution on weights
continuous versus mixture distribution on scale parameters
Other mixtures (sub populations?) on scales and \(\boldsymbol{\beta}\)?
Be careful about what predictors or transformations are used in the model as some outliers may be a result of model misspecification!