Lecture 9: Gibbs Sampling and Data Augmentation
STA702
Truncated Normal Sampling
sample from independent truncated normal distributions for full conditional for \(Z_i\)
if \(Y_i = 1\) then \(Z_i \sim \textsf{Normal}(x_i^T\beta, 1) I(0, \infty)\)
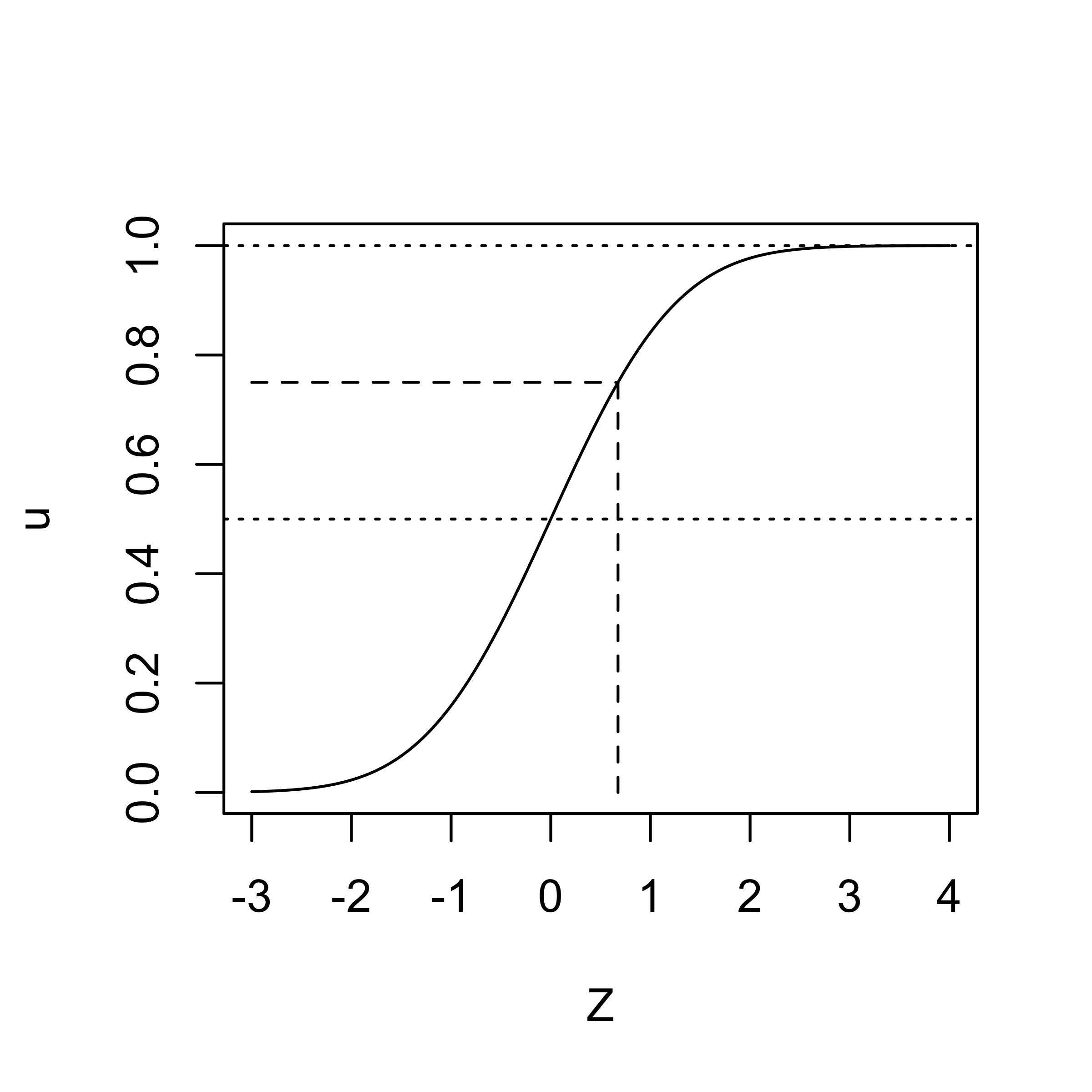
standard truncated normal \(\tilde{Z} = Z_i - x_i^T \beta \in (-x_i^T \beta, \infty)\)
Generate \(U \sim \textsf{Uniform}(\Phi(-x_i^T\beta), \Phi(\infty))\)
Set \(\tilde{z} = \Phi^{-1}(U)\) (Standard truncated normal)
Shift \(Z_i = x_i^T \beta + \tilde{z}\)
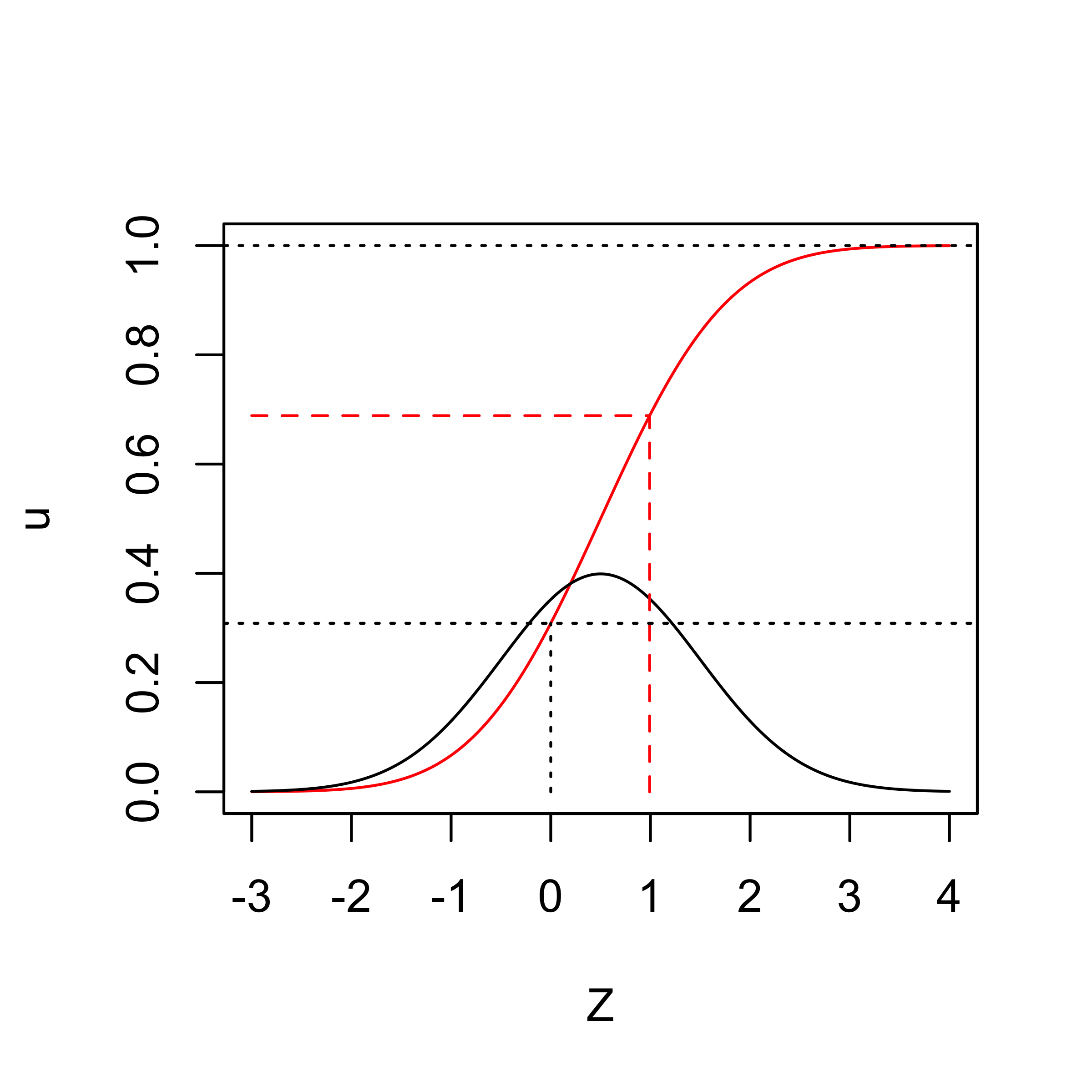
- U = 0.69, \(Z_i = x_i^T \beta + \Phi^{-1}(U)\) = 0.99
Data Augmentation in General
DA is a broader than a computational trick allowing Gibbs sampling
random effects or latent variable modeling i.e we introduce latent variables to simplify dependence structure modelling
Modeling heavy tailed distributions for priors or errors in robust regression as mixtures of normals
outliers
variable selection
missing data
Next class:
- Multivariate Normal data
- Wishart and inverse-Wishart distributions
- missing data
- Multivariate Normal data
Comments on Gibbs
Why don’t we treat each individual \(\theta_j\) as a separate block?
Gibbs always accepts, but can mix slowly if parameters in different blocks are highly correlated!
Use block sizes in Gibbs that are as big as possible to improve mixing (proven faster convergence)
Collapse the sampler by integrating out as many parameters as possible (as long as resulting sampler has good mixing)
can use Gibbs steps and (adaptive) Metropolis Hastings steps together
latent variables may allow Gibbs steps, but not always better compared to MH!