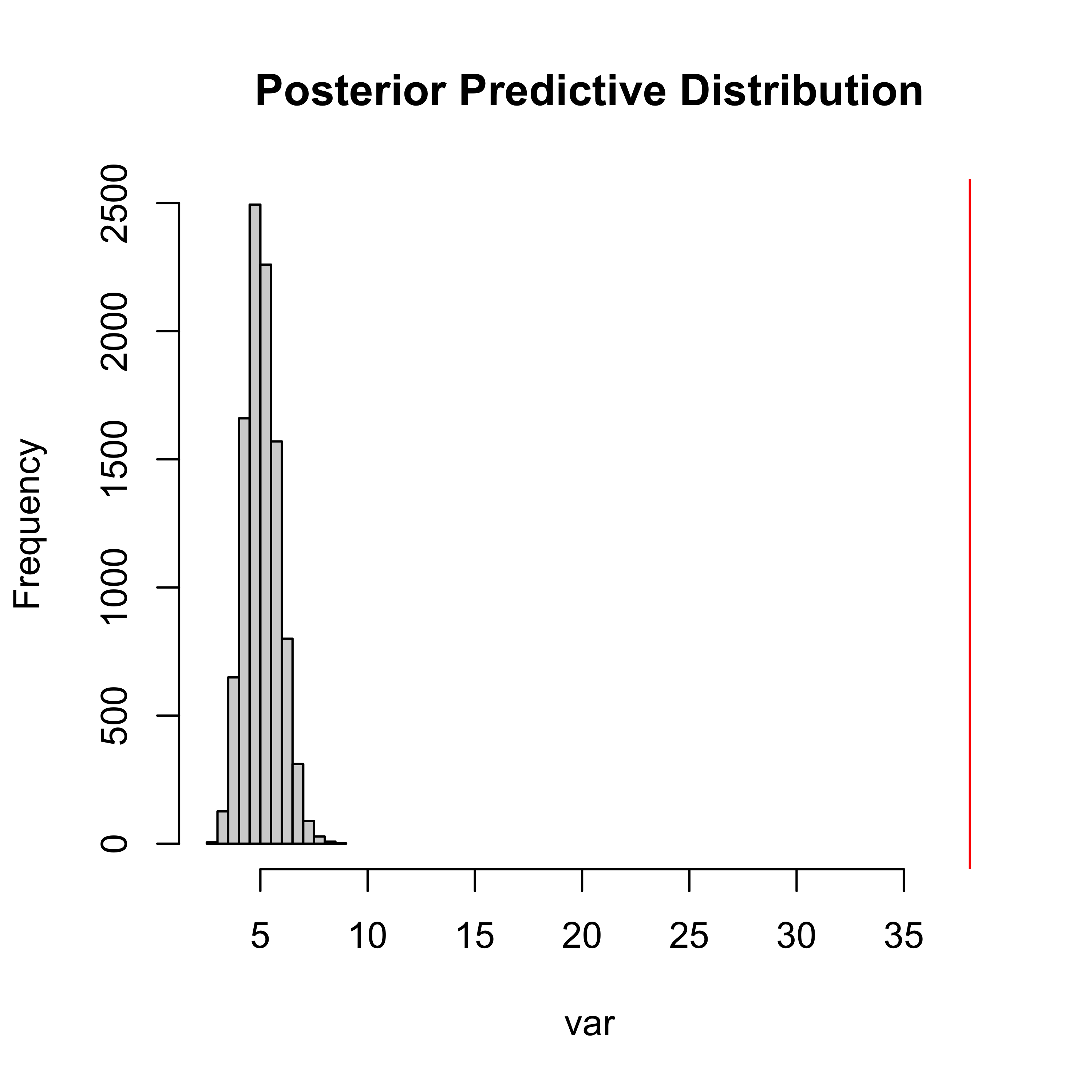
n = 100; phi = 1; mu = 5
theta.t = rgamma(n,phi,phi/mu)
y = rpois(n, theta.t)
a = 1; b = 1;
t.obs = var(y)
nT = 10000
t.pred = rep(NA, nT)
for (t in 1:nT) {
theta.post = rgamma(1, a + sum(y),
b + n)
y.pred = rpois(n, theta.post)
t.pred[t] = var(y.pred)
}
hist(t.pred,
xlim = range(c(t.pred, t.obs)),
xlab="var",
main="Posterior Predictive Distribution")
abline(v = t.obs, col="red")Prior/Posterior Checks
STA 702: Lecture 4
Example with Over Dispersion
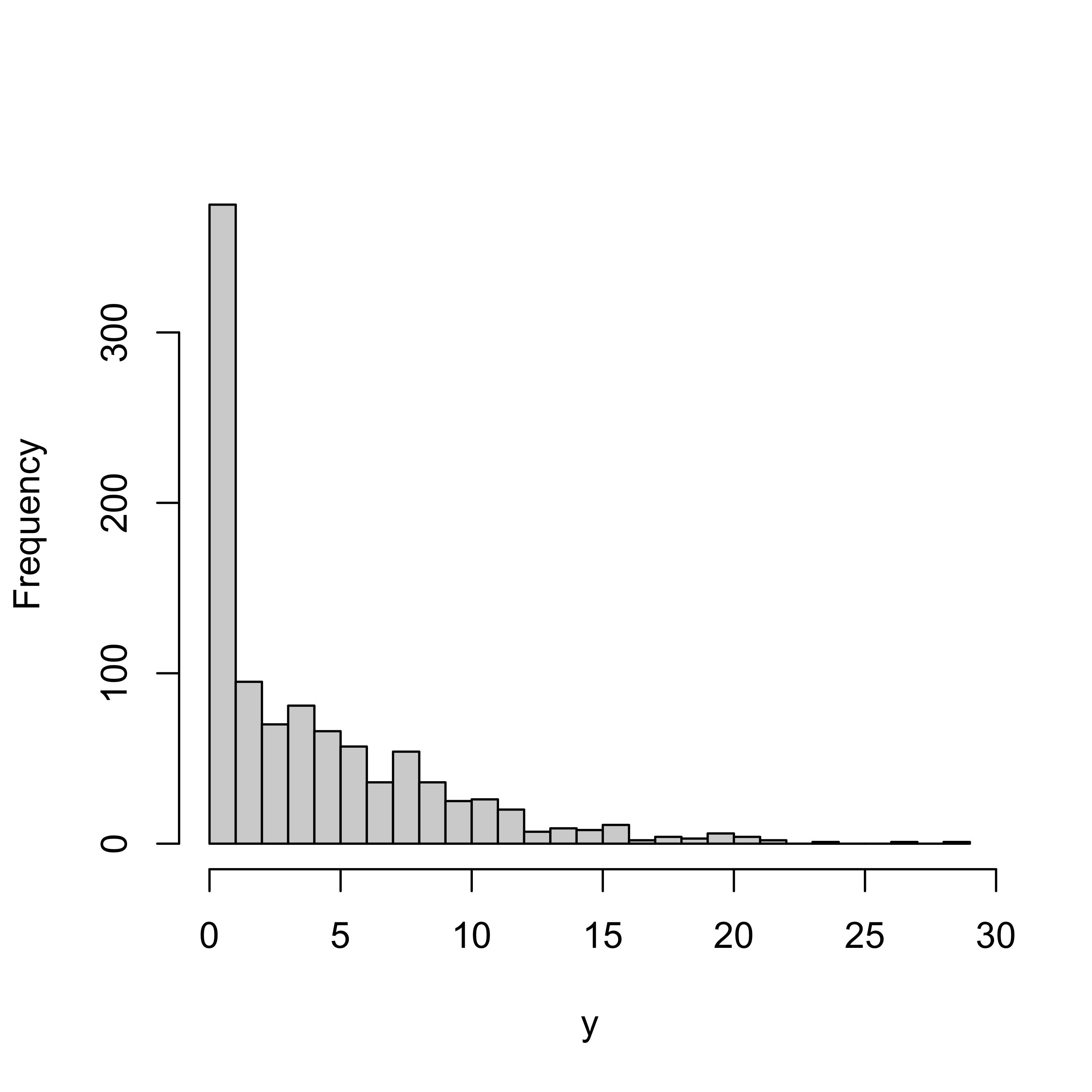
Zero Inflated Distribution
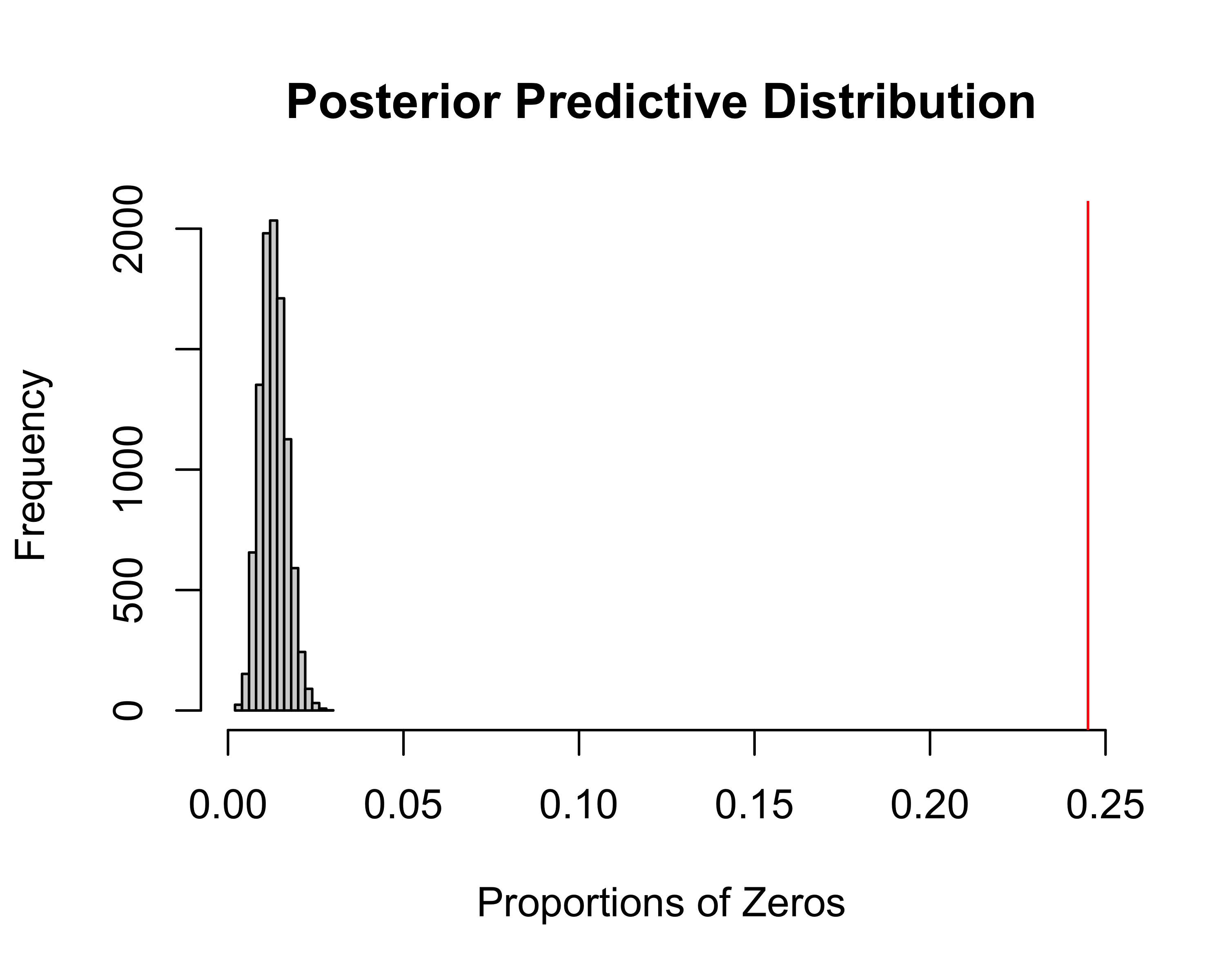
Posterior Predictive Distribution
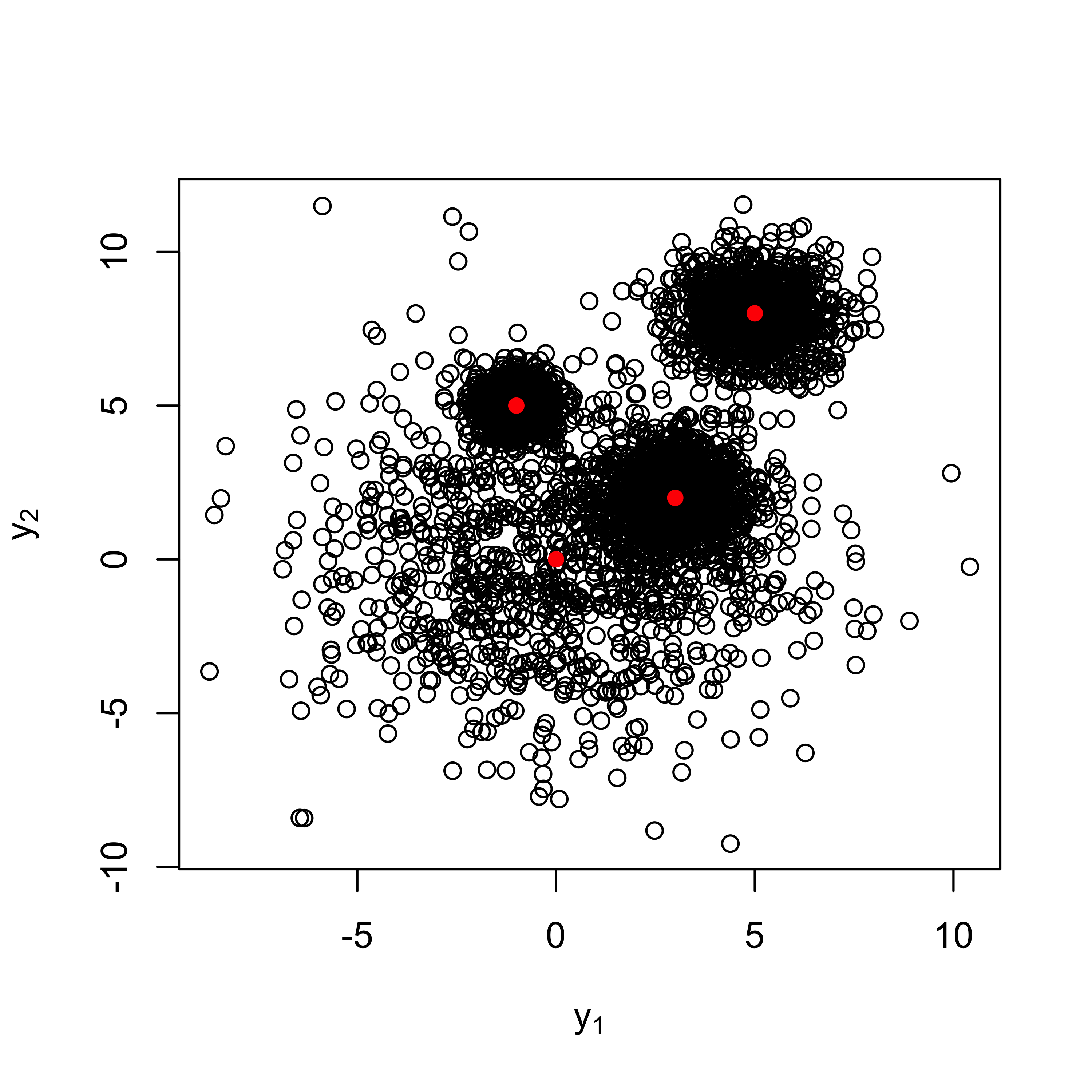
Example: Bivariate Normal
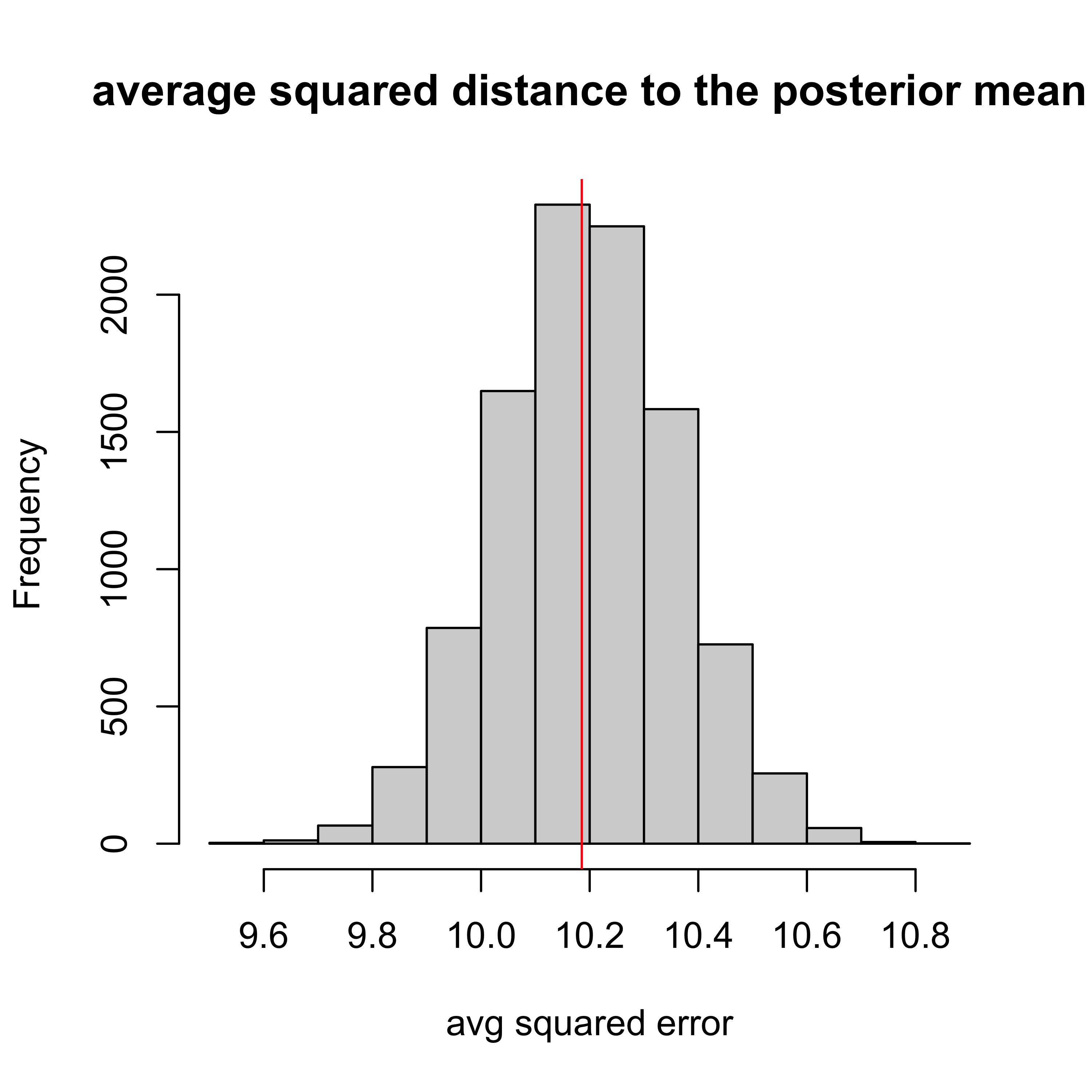
PPP = 0.52
What’s happening?
POP-PC of Moran et al
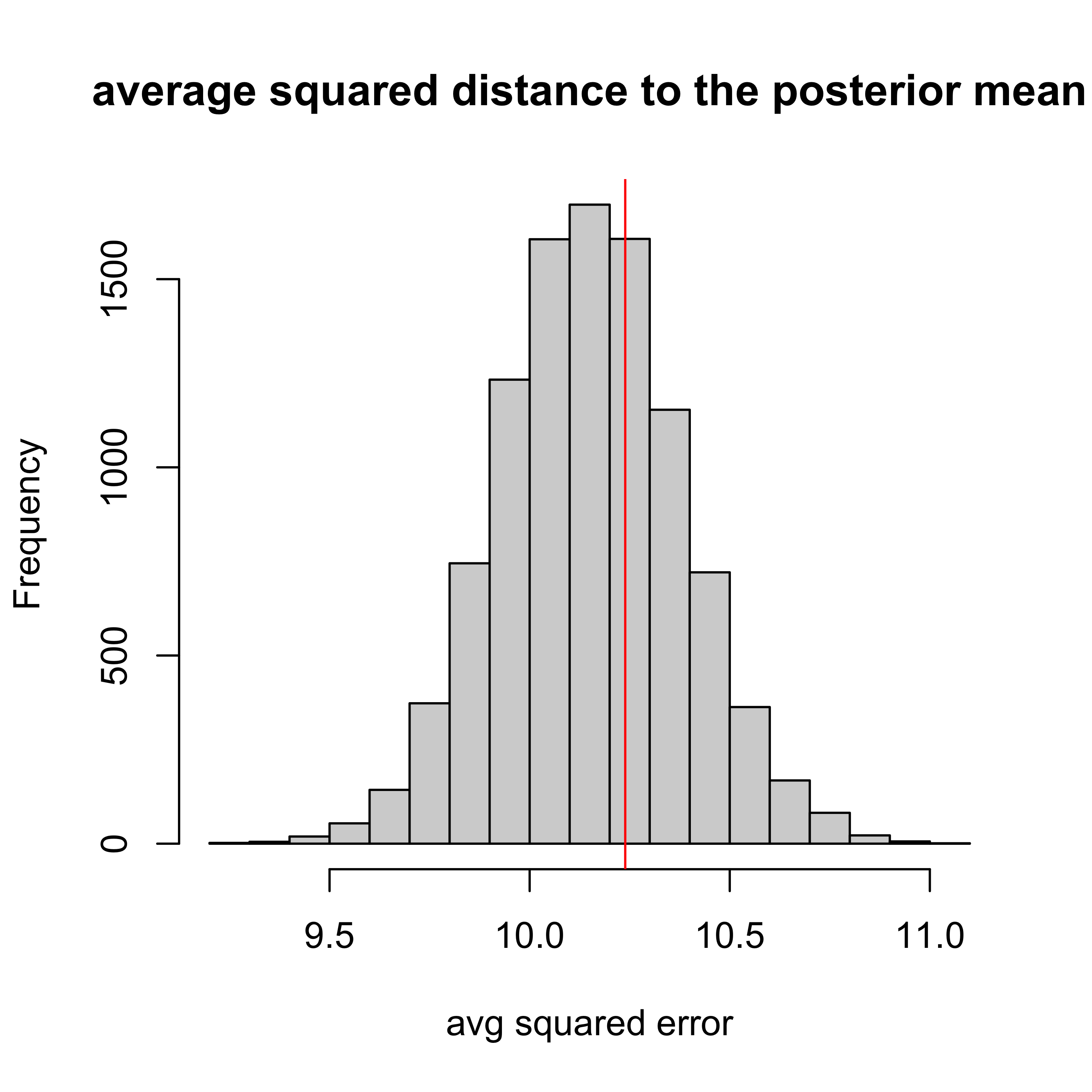
- POP-PPC = 0.35
Example
\[\theta_i \sim \textsf{Gamma}(\phi \mu, \phi)\]
Find pmf for \(Y_i \mid \mu, \phi\)
Find \(\textsf{E}[Y_i \mid \mu, \phi]\) and \(\textsf{Var}[Y_i \mid \mu, \phi]\)
Homework: \[\theta_i \sim \textsf{Gamma}(\phi, \phi/\mu)\]
Can either of these model zero-inflation?